
The Cacophony Index 1.0
Hi everyone, I’m Finn. I’ve been involved with Cacophony for a year now. I started out on work based around the Cacophonometers from a hardware and business model angle. Most recently I’ve been working on software and the development of a method to analyse all of this birdsong we’re getting! This post will describe the work I’ve done and basically what The Cacophony Index 1.0 is.
The purpose of the index is to tie together the data we’ve started to collect and use it to help understand how they are going. It can allow us to understand how well different predator control techniques are working and in turn improve them.
So, to analyse all this birdsong we need to be able to recognise it. This is a tricky challenge, birds can make all manner of songs. You can’t just pick all noises in a frequency range and be done with it.
The best answer to the problem, how to recognise birdsong in a low quality mp3 file, is that trendy concept everyone is talking about, Artificial Intelligence.
Aye eye?

AI - more specifically Machine Learning - is complicated, people all around world are working on ways to use machine learning to better recognise birdsong. But still no one has come up with a simple, reproducible method. So while machine learning isn’t out of the question, it’s a longer term goal for us.
It’s pretty clear machine learning is the only way we will accurately recognise birdsong. It’d be near impossible to create a non machine learning based algorithm that can recognise all the different types of birdsong heard in New Zealand!.
But what if we were to forget about identifying birdsong in particular and simplify the problem so it’s just a matter of identifying all noises above a certain volume?
Statistically speaking, the majority of all sounds that Cacophonometers are recording should be birdsong. What other sounds do you hear so often when away from urban areas? (of course if you start putting our Cacophonometers beside motorways then we’ll have a few problems!). If we assume that all noises above a certain amplitude could be birdsong and then take a measure of those recordings (ie. duration) we already have an index that will strongly correlate with the amount of birdsong in that soundscape (on the assumption that the majority of sound above x amplitude in the area is birdsong). We can assume that all the other sound events (animals, weather, people) are consistent across all of our recordings for each Cacophonometer.
So with this simplified challenge things are a lot easier. And that problem is what I’ve been working on!
I’ve created a method that labels all sound over a certain amplitude and within a certain time range. Here’s an example:

I then added an algorithm which allows us to recognise successive bursts of birdsong that weren’t being picked up because their duration was below our timeframe. But this is not perfect, sometimes we miss obvious song. Look at this one:
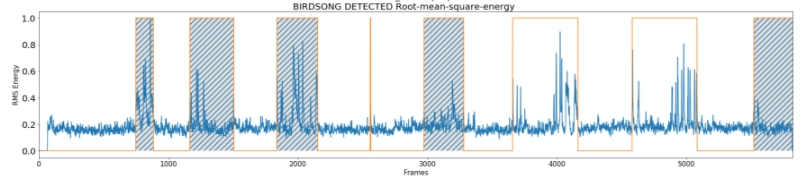
That non highlighted birdsong really does annoy me! But as long as these problems are consistent we can trust that our sample size is large enough to establish a running average. And then any improvements will only serve to improve the consistency of the average.
And that brings us to our next problem: what will our running average be based on? Our running average needs to correlate with the prosperity of birds in that soundscape.
We’ve thought about total volume (or more accurately, energy) as a measure, but then bird’s distance from the microphone becomes a factor. You could get really in depth and try to create a measure based on location, types of birds recorded, volume etc.
How about a simple measure of the length of birdsong recognised?
Of course this has it’s shortcomings (some birds make more/longer noise than others) but you have to start somewhere right? A measure of how much birdsong there is compared to data across a long period of time would help to give a fair idea of how that area’s overall bird population is doing.
So our Cacophony Index 1.0 is based on length of birdsong recorded but the process to recognise this birdsong in the recordings isn’t perfect. Great! There is a lot that we can improve. But we are making progress.
Now that we have a simple Cacophony Index working, we might as well start trying to apply machine learning to the problem. I believe the first step would be to apply it to the same problem I solved. With enough tinkering and data I’m sure a classifier would surpass the precision and recall of my simplified method. From there we can start using the latest research in the area of ‘bioacoustics’ to distinguish between birdsong and those other sounds, recognise different birds and even recognise different songs of the same bird. I think that as we improve the recognition process our Index will evolve. If we are able to recognise different birds then we can start to measure how well each species of bird is doing.
So this Index we have begun is just a starting point.
I came onto the project with the aim of getting the first Index up and running. My initial ideas were ambitious to say the least. However developing these ideas would take time and the birds wanted their Index now! We came up with a compromise that allowed us to start measuring birdsong ASAP but with the intention of continually improving our processes as time went on. Hopefully as we start to see results and realise where the index is most lacking, we can design subsequent Indexes based on that. To top it all off, this is an open source project. All my work is on Github so anyone can play around with it, improve it (please do!) and work on new iterations.
If you have ideas but don’t want to write the code feel free to get in touch with me. I’d love to hear from you.
We hope that in time we’ll have many who’ve contributed to the Cacophony Index, otherwise we might as well call it a ‘Finndex’...